
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- node.js
- mongoose
- OOAD
- sequelize
- MongoDB
- python
- mysql
- Network
- S3
- wireshark
- AWS
- Android
- Kotlin
- macos
- Scheduling
- OS
- linux
- Util
- HTML
- typeorm
- DATABASE
- Express
- algorithm
- Crawling
- ubuntu
- css
- postman
- docker
- React
- TypeScript
- Today
- Total
SW
[Python] 크롤링이란? 예시로 크롤링 이해하기 본문
크롤링(Crawling)이란?
크롤링이란 쉽게 설명하면 웹사이트에서 내가 원하는 데이터를 추출하는 것이다. 크롤링이라는 의미의 이해를 돕고자 예시를 가져왔다.
- 특정 쇼핑몰 인기순위 top10 제품의 이름과 가격 가져오기
- 네이버 블로그 검색 결과 가져오기
- 특정 인터넷 기사의 기사 제목 가져오기
- 쿠팡 검색창에서 노트북 검색 후 상위 4개 상품의 상품명 가져오기
이처럼 사용자가 원하는 웹사이트에 들어가서 원하는 데이터를 추출하여 가져오는 것을 말한다. 파이썬은 크롤링을 위한 많은 라이브러리를 제공하고 있으며 라이브러리를 통해 편리하게 크롤링 기능을 구현할 수 있다. 주로 파이썬에서 크롤링을 위해 필요한 라이브러는는 requests, BeautifulSoap 이다.
requests library
페이지를 가져오기 위한 라이브러리이다.
BeautifulSoap library
가져온 웹페이지를 기반으로 사용자가 원하는 데이터를 추출할 수 있도록 도와주는 라이브러리이다.
이제 해당 라이브러리를 이용해서 특정 인터넷 기사의 기사 제목 가져오기 기능을 실제로 구현해보자.
# 크롤링을 위한 라이브러리
import requests
from bs4 import BeautifulSoup
# 웹사이트 가져오기
res = requests.get("https://news.v.daum.net/v/20220201163539498")
# 가져온 웹사이트 파싱하기
soup = BeautifulSoup(res.content, 'html.parser')
# 파싱된 페이지를 이용해서 원하는 데이터 추출하기
data = soup.find(class_="tit_view")
print(data.text)필자는 예시로 daum 이라는 웹사이트의 뉴스에서 특정 인터넷 기사의 제목을 가져왔다.
requests 라이브러리의 get() 메서드를 이용해서 가져오고자 하는 웹사이트를 가져온 뒤 bs4를 이용해서 가져온 웹사이트를 HTML parser를 이용하여 파싱을 했다.
HTML parser를 이용하면 html 태그나 id, class값과 같은 속성들을 이용해서 태그에 담긴 값을 쉽게 가져올 수 있다.
따라서 필자는 파싱된 데이터에서 find() 메서드를 이용하여 클래스명이 tit_view 인 것을 찾아 해당 태그 안에 들어있는 값을 추출한 것이다. 추출한 데이터를 출력하기 위해서는 data.get_text() 또는 data.text 를 사용하면 된다.
크롬 검사 페이지를 통해서 확인하기
실제로 tit_view라는 클래스 명을 가진 태그 안에 우리가 가져온 기사 제목이 있었는지 확인하기 위해서는 크롬의 검사 페이지를 이용하면 쉽게 찾아볼 수 있다. 먼저 해당 웹사이트에서 마우스 오른쪽을 클릭 후 검사 탭을 클릭하거나 F12 를 누르면 다음과 같은 화면이 나타난다.
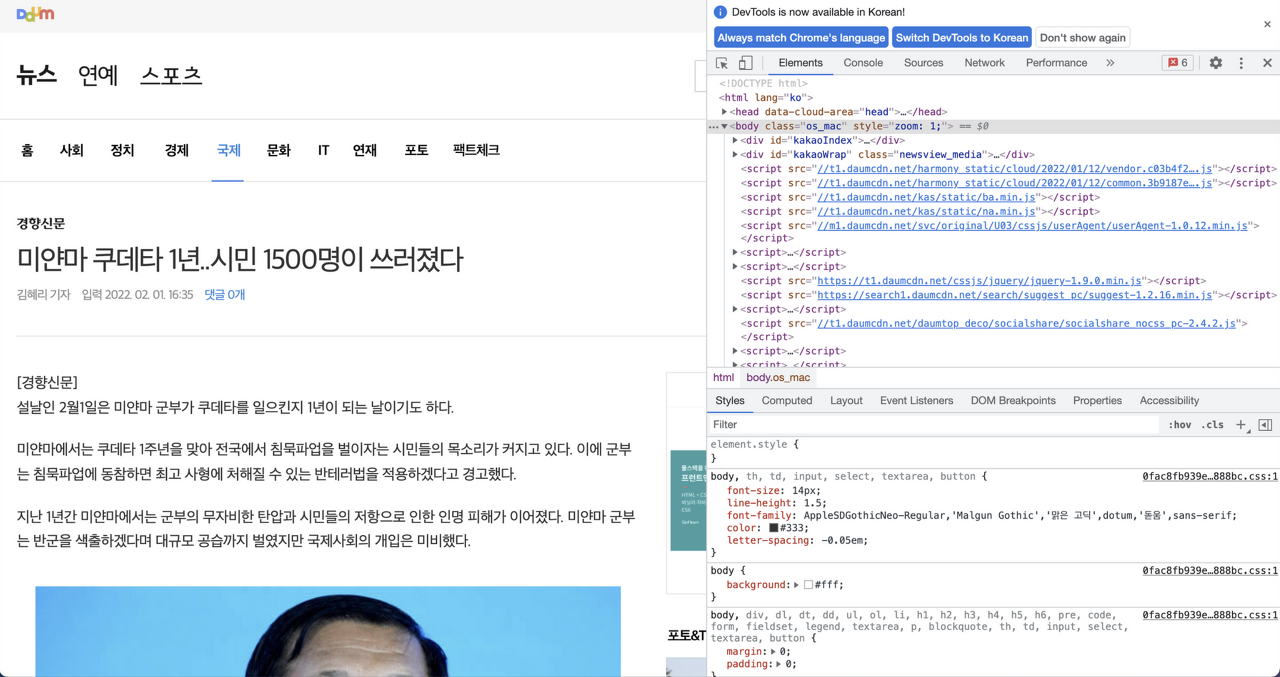
검사 페이지는 사용자가 현재 들어와있는 웹페이지의 html이 어떻게 구성되어 있는지 확인할 수 있다.
이제 body태그 하위에 tit_view 이름의 클래스를 가진 태그를 찾아보면?

h3태그의 클래스명이 tit_view인 것을 확인할 수 있으며 값으로 기사 제목이 있는 것을 확인할 수 있다.
BeautifulSoap 에서 제공하는 여러 추출 메서드가 존재하지만 이번 포스팅 글에서는 find() 메서드를 예시로 살펴봤으며 다음 글에서는 다양한 메서드를 알아볼 것이다.
'Python' 카테고리의 다른 글
| [Python] 크롤링으로 네이버 국내 증시 코스피 항목 추출하기 (0) | 2022.05.08 |
|---|---|
| [Python] CSS selector를 이용하여 Daum 뉴스기사 제목 크롤링하기 (0) | 2022.05.08 |
| [Python] HTML 코드를 이해하여 크롤링 다루기 (0) | 2022.05.08 |
| [Python] 리스트, 튜플, 셋, 딕셔너리 정리하기 (0) | 2022.05.07 |
| Fast API란? 튜토리얼을 통해 이해하기 (0) | 2022.05.07 |



