
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- algorithm
- linux
- mongoose
- HTML
- Network
- sequelize
- ubuntu
- docker
- css
- MongoDB
- OOAD
- S3
- TypeScript
- Android
- AWS
- DATABASE
- wireshark
- node.js
- Util
- macos
- Scheduling
- Express
- OS
- postman
- mysql
- Crawling
- React
- Kotlin
- typeorm
- python
- Today
- Total
SW
[Python] 크롤링으로 네이버 국내 증시 코스피 항목 추출하기 본문
이번 글에서는 네이버 주식 국내 증시 중 코스피 시가총액 상위 50개 종목명과 현재가를 크롤링하는 예제를 살펴보고 추출한 데이터를 csv파일로 저장하는 방법을 알아본다.
해당 페이지로 들어가면 코스피에 상장된 기업들이 시가 총액 순으로 정렬된 페이지가 나타난다.

필자는 해당 페이지에서 종목명, 현재가를 크롤링으로 추출해보고자 한다. 먼저 F12 또는 오른쪽 마우스 클릭 후 검사 탭을 눌러 개발자 도구를 연다.

그 다음으로 기업들이 어떤 태그에 묶여있는 지 확인해봤더니 tbody라는 태그에 속한 것을 확인할 수 있었다. 이제 삼성전자라는 키워드가 어떻게 구성되어 있는지 살펴보자. 개발자 도구 왼쪽 상단 커서 아이콘을 클릭 후 삼성전자 단어를 클릭한다.

구조를 CSS selector로 나타내보면 삼성전자 라는 텍스트는 tbody > tr > td:nth-child(2) > a로 구성된 것을 알 수 있다.
조금 더 자세하게 선언하면 tbody > tr:nth-child(2) > td:nth-child(2) > a형식으로도 선언할 수 있다.
nth-child(n) 란 무엇일까?
부모안에 모든 요소 중 n번째 요소를 나타낸다. 예를 들어 위의 경우를 살펴보면 2번째 tr태그 밑에는 여러 개의 td태그가 존재한다. 그 중에서 우리는 종목명을 가져와야 한다. 종목명은 tr태그 아래에 2번째 td태그에 속해 있으므로 td:nth-child(2)를 통해서 값을 가져올 수 있다.
이 내용을 바탕으로 해당 종목의 현재가를 가져오려면 CSS selector를 어떻게 구성해야 할까?

tbody > tr 까지는 동일하지만 현재가는 3번째 td태그에 위치하고 있으므로 tbody > tr > td:nth-child(3)으로 선택자를 선언할 수 있다. 이제 실제로 크롤링 코드를 구현해보자.
상위 50개 종목 크롤링하기
시가총액 기준 상위 50개 종목과 해당 종목의 현재가를 크롤링하기 위해서는 다음과 같이 코드를 작성할 수 있다.
import requests
from bs4 import BeautifulSoup
res = requests.get("https://finance.naver.com/sise/sise_market_sum.naver?&page=1")
soup = BeautifulSoup(res.content, 'html.parser')
# 첫번째 페이지에 노출된 종목명 가져오기
company = soup.select('tbody > tr > td:nth-child(2) > a')
# 해당 종목들의 현재가 가져오기
market_price = soup.select('tbody > tr > td:nth-child(3)')
for company, price in zip(company, market_price):
print(company.text, price.text)파이썬에서 제공하는 zip() 메서드를 이용하면 반복문을 사용할 때 2개의 리스트 변수를 사용할 수 있게 해준다.
출력을 하면 1페이지에서 추출한 50개 종목과 해당 종목들의 현재가를 확인할 수 있다.

위 결과는 50개 결과 중에서 상위 5개 결과를 가져온 이미지이다.
결과를 CSV 파일로 저장하기
추출한 데이터를 .csv 파일로 저장하기 위해 pandas라이브러리를 이용했다. 코드는 다음과 같이 구현할 수 있다.
- pip install pandas
# 라이브러리 import
import pandas as pd
# 추가로 구현된 코드
dataset = []
for company, price in zip(company, market_price):
dataset.append([company.text, price.text])
df = pd.DataFrame(dataset, columns=["종목명","현재가"])
df.to_csv('result.csv', index=False, encoding="utf-8")코드를 실행하면 result.csv 파일이 생성되며 내용은 다음과 같다.
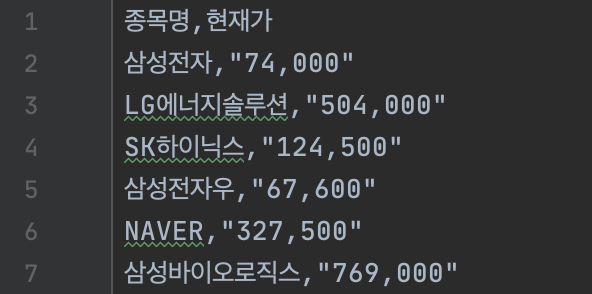
맨 위에 컬럼명이 정의되어 있으며 아래로 50개의 데이터가 저장된 것을 확인할 수 있다. (위 이미지는 결과의 일부를 가져온 이미지이다.)
'Python' 카테고리의 다른 글
| [Python] 네이버 Open API 파이썬 코드로 구현하여 사용하기 (0) | 2022.05.08 |
|---|---|
| [Python] 크롤링 데이터 엑셀 파일(xlsx)로 저장하기 (0) | 2022.05.08 |
| [Python] CSS selector를 이용하여 Daum 뉴스기사 제목 크롤링하기 (0) | 2022.05.08 |
| [Python] HTML 코드를 이해하여 크롤링 다루기 (0) | 2022.05.08 |
| [Python] 크롤링이란? 예시로 크롤링 이해하기 (0) | 2022.05.08 |



